
I had different agents play ‘The Password Game’ - they didn’t do so well
The Password Game
The Password Game is a kafkaesque masterpiece of absurdity. The goal is simple: create a password that satisfies all the rules, which get increasingly obtuse.
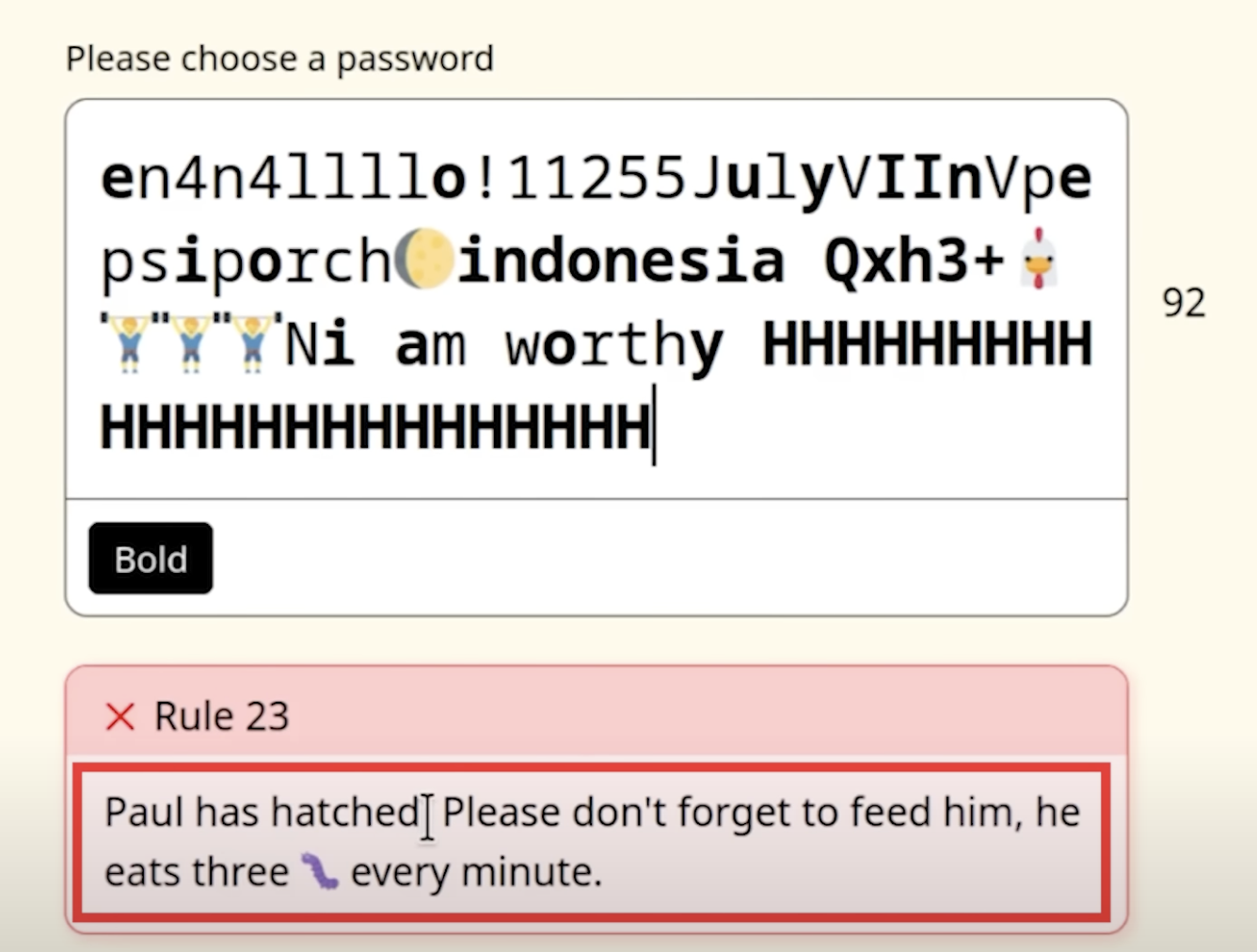
The best way to get a feel for it is simply to try it yourself. There are insane videos of people getting through all 35 rules. Some absurd tasks include solving captchas, playing chess, geoguessing, and my favourite - keeping Paul 🐔 alive..
Multimodal Agents
2025 seems to be the year of Agents™️, even though no one really agrees on what they really are. With all the hype around agents, it’s hard to truly know what these things can actually do or not.
This is where ‘The Password Game’ comes in. A few requirements make it particularly interesting:
- It requires vision capabilities
- It requires interacting with a webpage
- It requires reasoning through conflicting rules
It’s also very easy to understand. While solving it is difficult, the rules themselves are mostly clear and concise.
You can also observe in real-time where multimodal agents might stumble and what reasoning led to it. And since the rules increase incrementally in difficulty, we can basically just keep track of how far an agent is able to get in the game to measure performance.
The Setup
A recent library, browser use, has made setting this all up pretty easy. It takes screenshots of the browser and overlays elements on screen that the model can then interact with via tool use. It takes care of all the heavy-lifting. You just have to define a task for the LLMs. Here’s what the LLMs “see”:
I purposefully made the task prompt super simple - there are already plenty of prompts under the hood of browser-use
and the goal is to see how an agent performs with very little direction on the actual task:
TASK = """
Go to https://neal.fun/password-game/ and find an appropriate password that satisfies the criteria.
Keep track of the highest rule number that has been satisfied explicitly in a variable in memory, e.g. MAX_RULE=1.
"""
Because I don’t have access programatically to the game itself, I figured I’d just let the LLM keep track of its own score, which I could then parse from the history. This ended up working most of the time, though I did have to intervene sometimes (more on that later).
Results
Here’s an example of gpt-4o attempting the password game. I added the textbox with the model’s thoughts and actions on top.

It starts off really strong, breezing through the captcha, sponsor logo and Roman Numerals. However, once the Captcha is solved, it then struggles to get the digits to add to 25 once more and just gets stuck endlessly mashing things.
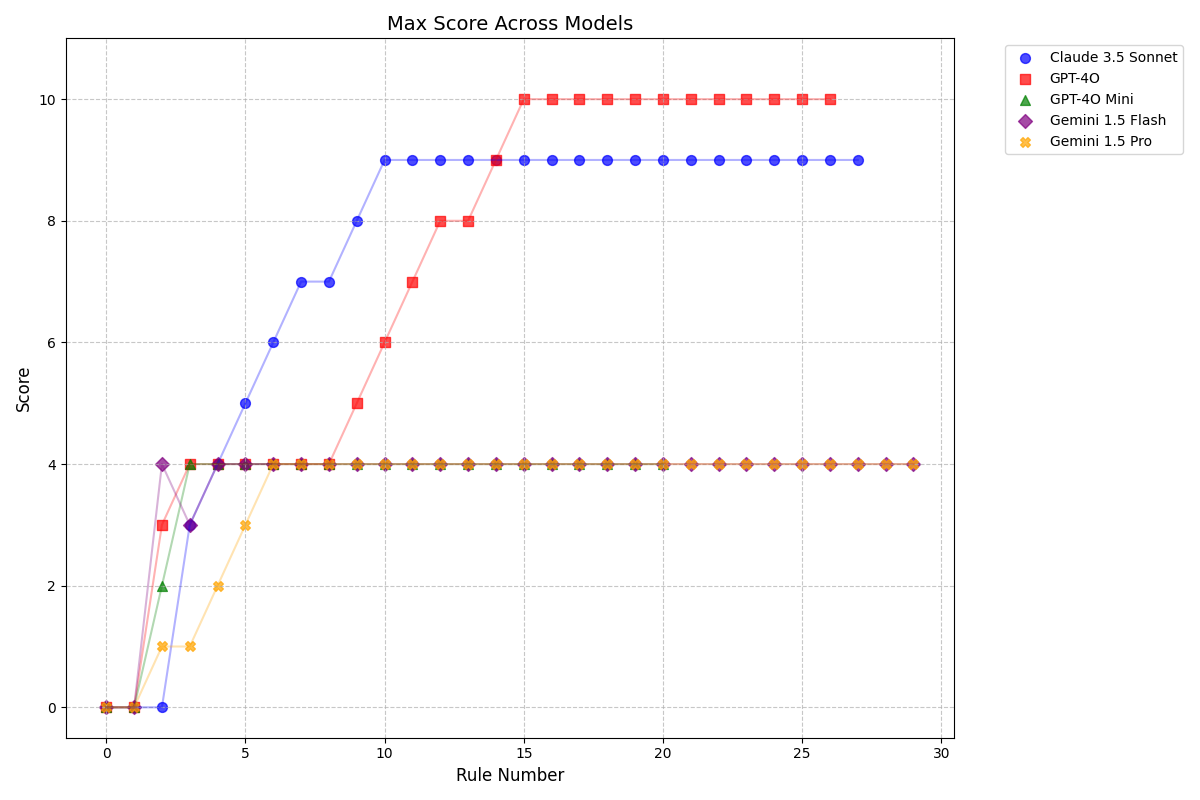
I evaluated different models and providers for a maximum of 30 steps. I only ran each model once (running these evals is not cheap!), though I’m sure you might get different results averaging over many runs. Here are the results I got:
Below, you can scroll through the replays for each one of the attempts:
Breezing through the captcha, but struggles with digit sum rule after that.

Fools itself into thinking it solved the captcha, and then terminates the task early.

Can't get past the digit sum rule. Tries to scroll down the page for some reason.

Can't get past the digit sum rule.

Can't get past the digit sum rule.
Some interesting observations:
gpt-4o-mini,gemini-1.5-flashandgemini-1.5-procan’t make it past summing digits to 25 rule.gemini-1.5-prodoesn’t seem to keep anything useful in its previous memoriesgpt-4obreezes through the first series of rules including the captcha. It then gets caught up on summing to 25 again and can’t get past that.claude-3-5-sonnetdoesn’t make it past the captcha. It does fool itself into thinking it solved it, and falsely incremented its counter which I had to correct. It even terminated the task prematurely assuming it was all done!
Of course, this is just based on a single run for each model and is not statistically significant. I’m sure running them multiple times would yield different results. But part of me was hoping some of these models would make it much further on a first try.
Though it might be tempting to add more instructions to the prompt, part of the point of this exercise is to see how much the agents can figure out on their own.
Keep in mind also that these models are first and foremost trained on text. This task specifically involves parsing the text from the image, and then acting on it. Interestingly enough, from the logs, the “reading” part does not seem to be too problematic. Coordinating the interpretation, reasoning and acting on some of the observations seems to be much harder. In some cases it feels like the brain tells it to do something, but the limb just doesn’t act accordingly.
If you want to replicate the experiments, you can find the code here
Conclusion
“The Password Game” in its current form is currently too hard for multimodal agents. It might just be a really good benchmark, assuming it doesn’t become too popular and people don’t start gaming it.
It could be that the models themselves are not properly trained to handle this kind of reasoning just yet.
It could also be that the agentic methods of browser-use are not optimal for this kind of setup.
One thing is for sure, I will be using this as a personal benchmark for future multimodal agents!
Comments